ブラインド音源分離を悪用した盗聴に対する音響ジャミングの検討
- 中嶋 大志 (東京都立大学)
- 第12回 SPEASIP ワークショップ
- 2026年3月4日(水) 11:00–12:20, ポスターEA3
背景
スマートスピーカ,会議支援,ウェアラブル端末などの普及により,実空間での音声プライバシー保護は以前より重要になっています [1], [2], [3]。従来の建築音響では,銀行や薬局のような機密会話が発生する空間で,天井・壁面スピーカからマスキング音を流して「人の聞き取り」を難しくする手法が広く使われています [4], [5]。
一方で,攻撃者がマイクロホンアレイを使う場合,従来マスキング音は必ずしも十分ではありません。空間的に固定されたマスキング音は,多チャネル処理や BSS(Blind Source Separation)で抑圧・分離される可能性があります [6]。さらに,分離結果を自動音声認識(ASR)へ入力すれば,機械的な盗聴により会話内容の復元が進み,機密情報の漏えいやディープフェイク悪用につながるリスクが高まります [7], [8], [9]。

図: 盗聴シナリオの概念図
目的
本研究の目的は,BSS を悪用する盗聴者に対して,分離処理そのものを失敗しやすくする音響ジャミング信号を設計することです。特に,AuxIVA が前提とする「音源間の統計的独立性」を意図的に崩すことで,分離性能(SI-SDR)と盗聴後の認識性能(WER)を悪化させることを狙います [10], [11], [12], [13], [14]。
方法
想定する攻撃シナリオは次のとおりです。攻撃者は遠方に固定したマイクロホンアレイで混合音を収録し,AuxIVA で話者ごとに分離してから ASR に入力し,会話内容を復元します [7], [8], [9]。
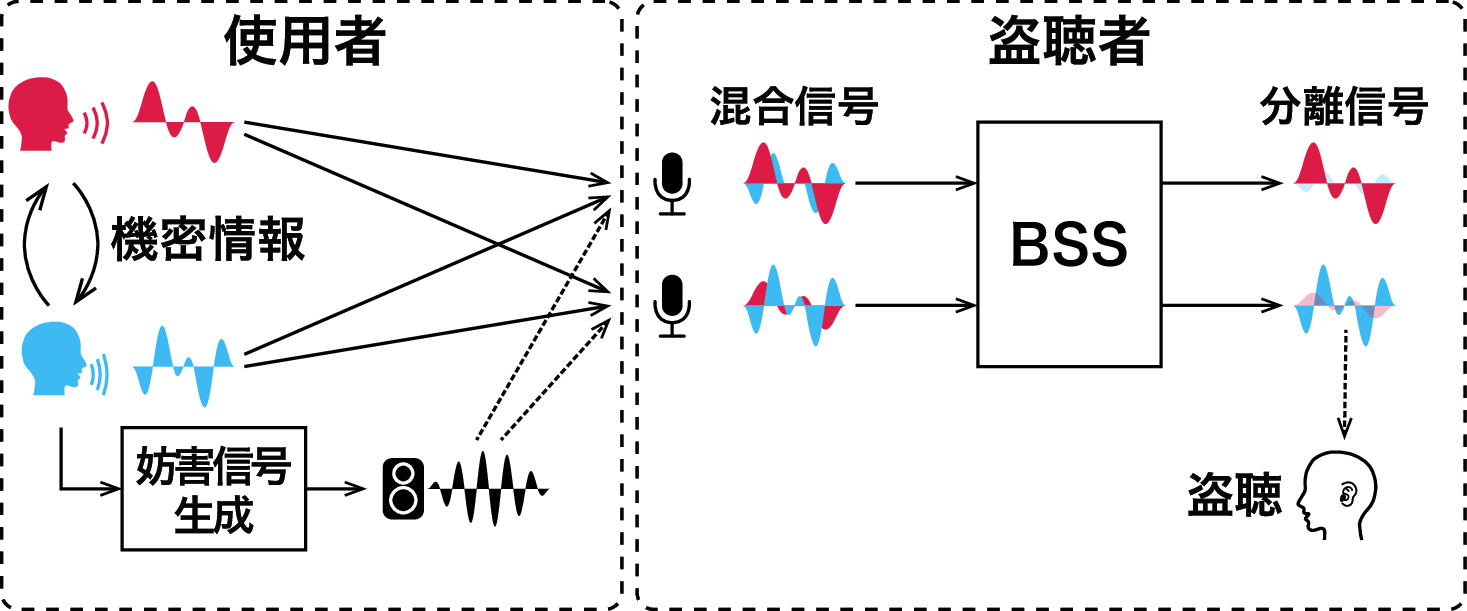
図: 会話場近傍のスピーカと遠方の攻撃者による盗聴シナリオ
STFT 領域の観測モデルは,音源数を $K$,マイクロホン数を $M$ として,次で表します。
\[\boldsymbol{x}_{f,t}=\sum_{k=1}^{K}\boldsymbol{a}_{k,f}\,s_{k,f,t}\in\mathbb{C}^{M}\]ここで,$s_{k,f,t}$ は第 $k$ 音源の STFT 係数,$\boldsymbol{a}{k,f}$ は対応するステアリングベクトルです。分離行列を $\boldsymbol{W}_f$,第 $m$ 行の分離ベクトルを $\boldsymbol{w}{m,f}^{\mathrm{H}}$ とすると,AuxIVA の目的関数は次の $J^{+}$ で定義されます [12], [13]。
\[r_{m,t}=\sqrt{\sum_{f=1}^{F}\left|\boldsymbol{w}_{m,f}^{\mathrm{H}}\boldsymbol{x}_{f,t}\right|^2}\] \[\boldsymbol{V}_{m,f}=\frac{1}{T}\sum_{t=1}^{T}\varphi\!\left(r_{m,t}\right)\boldsymbol{x}_{f,t}\boldsymbol{x}_{f,t}^{\mathrm{H}}\] \[J^{+}=\sum_{f=1}^{F}\left(\sum_{m=1}^{M}\boldsymbol{w}_{m,f}^{\mathrm{H}}\boldsymbol{V}_{m,f}\boldsymbol{w}_{m,f}-\log\left|\det\boldsymbol{W}_{f}\right|^{2}\right)\]重み関数は $\varphi(r)=\frac{\psi’(r)}{2r}$ で,時間変動複素ガウスモデルでは $\varphi(r)=\frac{F}{r^{2}}$ です [13]。
図: 音源モデルの模式図(左: 単一信号,右: AuxIVA モデル)
提案法では,このモデル仮定を悪用してジャミングを設計します。ジャミングを含む観測モデルを
\[\widetilde{\boldsymbol{x}}_{f,t}=\sum_{k=1}^{K}\boldsymbol{a}_{k,f}\,s_{k,f,t}+\boldsymbol{b}_{f}\,z_{f,t}\]とし,話者近傍で得た信号の STFT 係数 $s_{k,f,t}$ から,周波数方向の包絡
\[\alpha_t=\sqrt{\frac{1}{F}\sum_{f=1}^{F}\left|s_{k,f,t}\right|^{2}}\]を計算して,位相を保持したまま
\[z_{f,t}=\alpha_t\exp\!\left(j\,\angle s_{k,f,t}\right)\]を生成します。これにより,AuxIVA が用いる統計的独立性の手がかりを崩し,誤分離を誘発します [12], [13]。
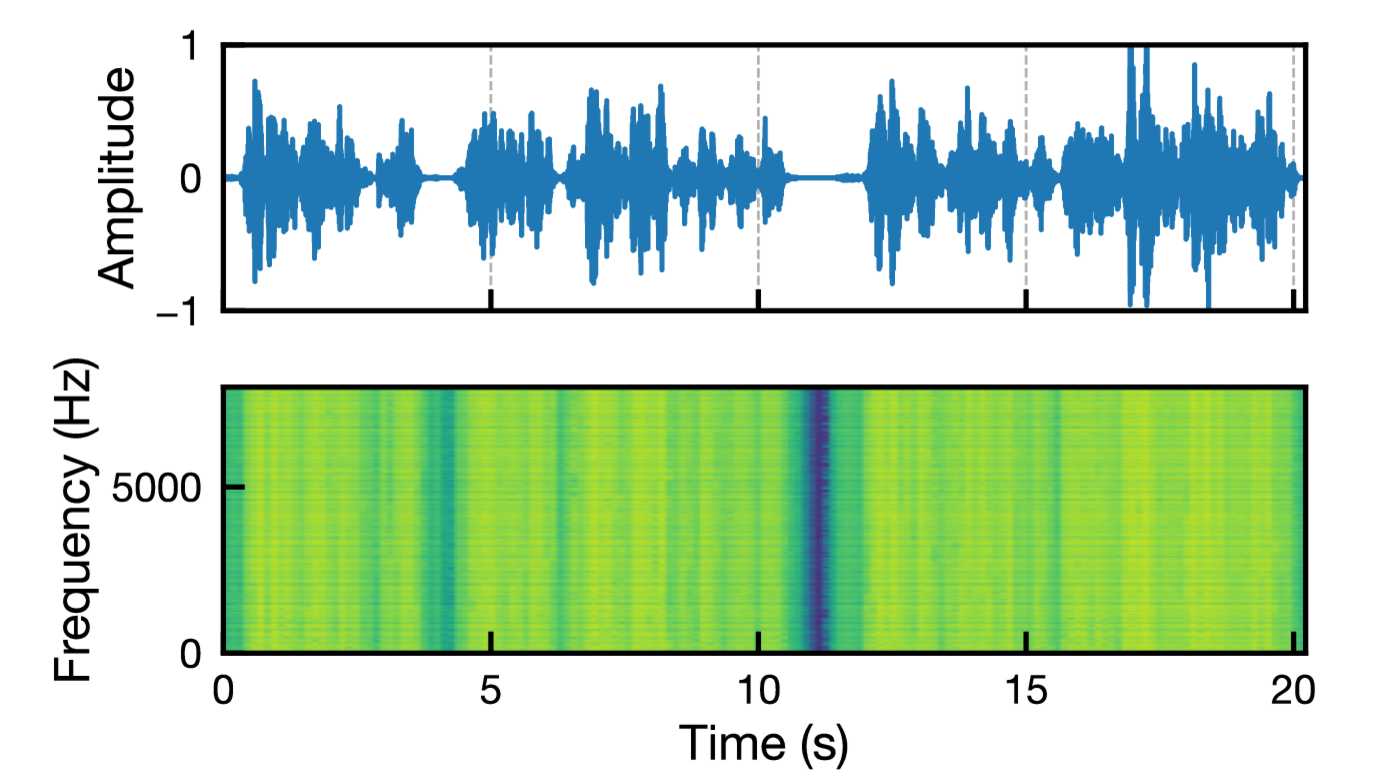
図: AuxIVA の音源モデルに従うジャミング信号の例
実験
シミュレーション条件
残響室シミュレーションには pyroomacoustics を使用しました [15]。 室サイズは 6.0 × 5.0 × 2.7 m,残響時間は $\text{RT}_{60}=0.2$ s です。 話者は 2 名とし,話者位置は一定範囲でランダムに変化させました。 攻撃者側は半径 0.04 m の 4ch 円形アレイを使用し,話者群から y 軸方向に 2.0 m 離した位置に設置しています。
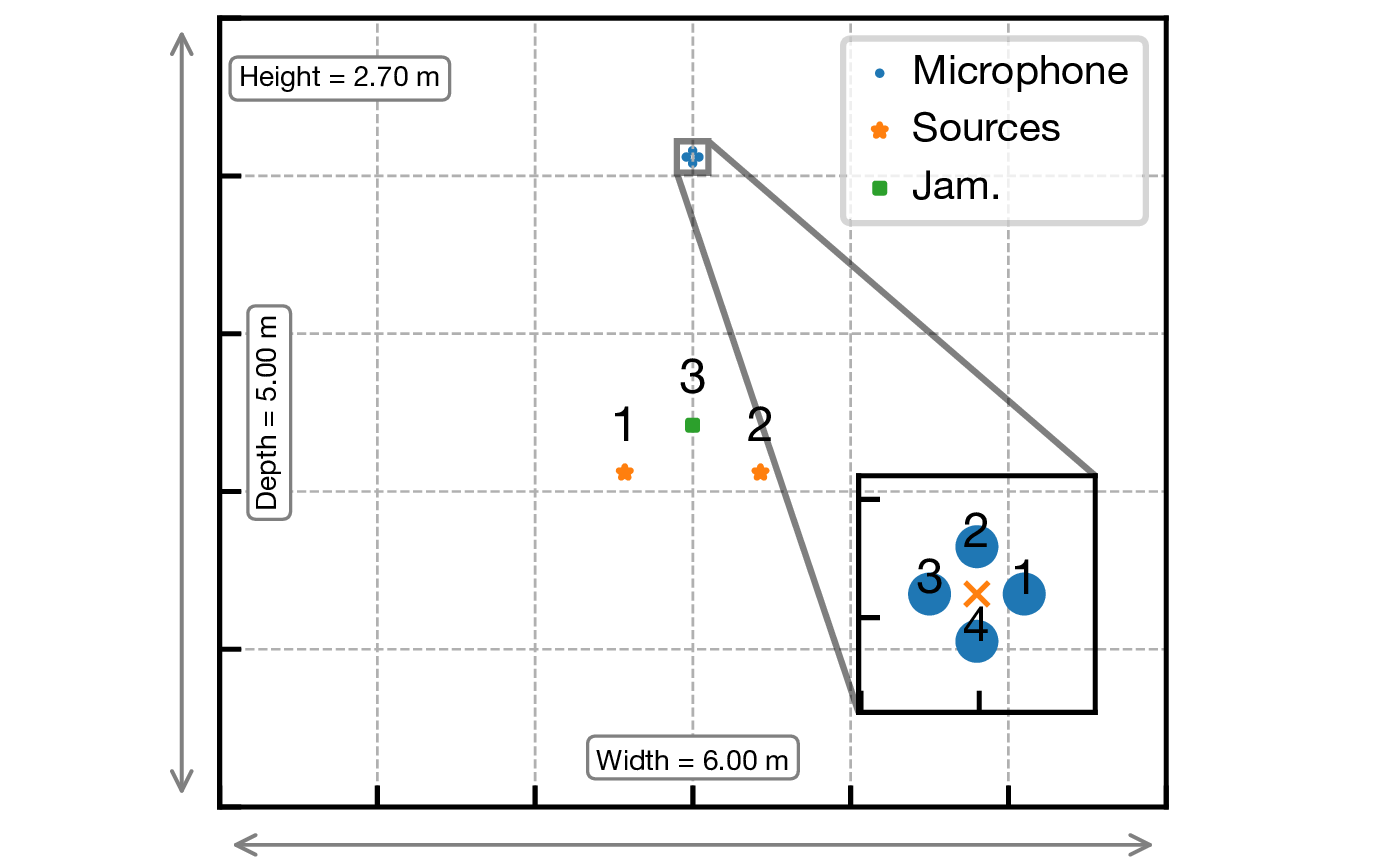
図: 話者間にジャミング信号用スピーカとアレイを配置した例
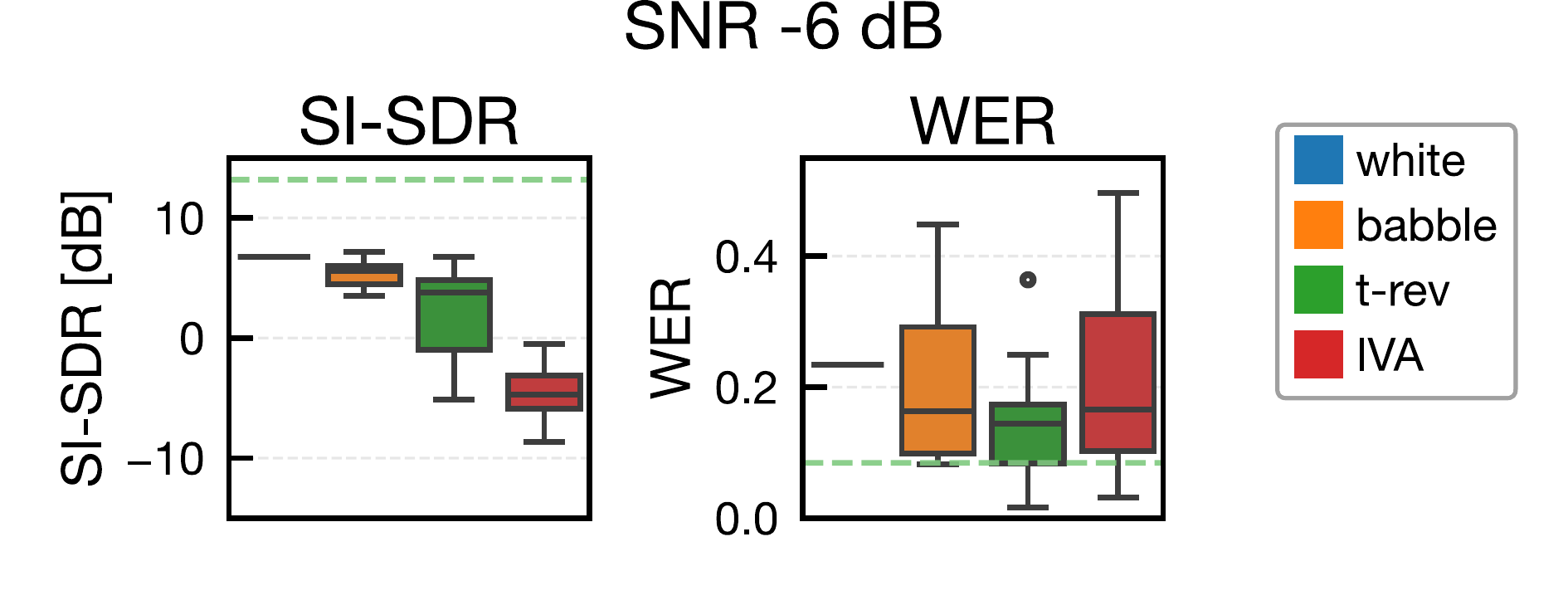
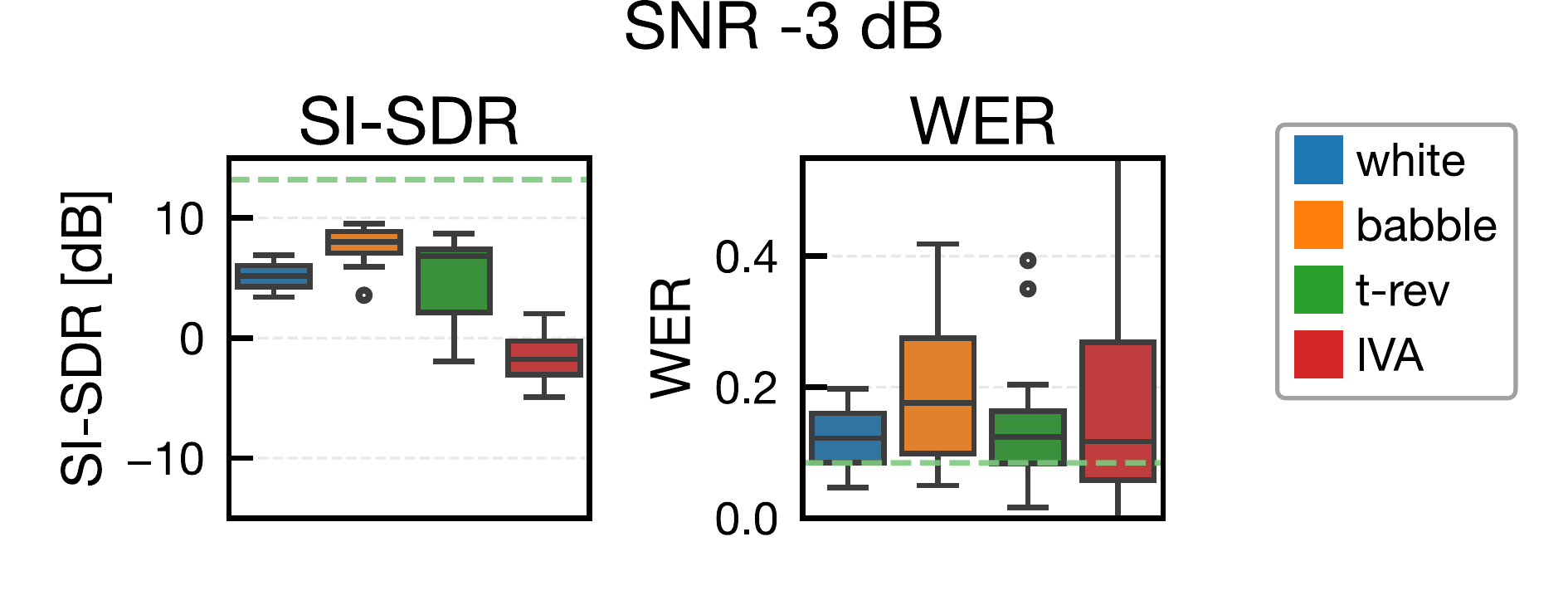
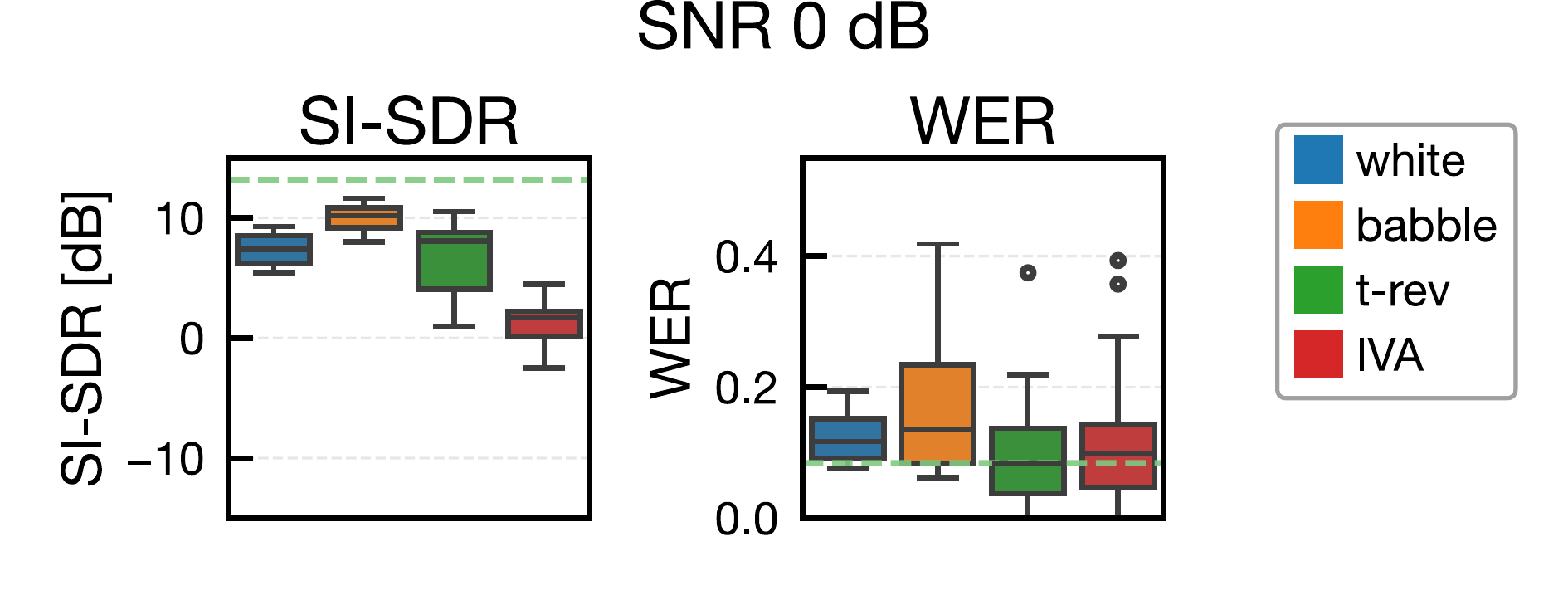
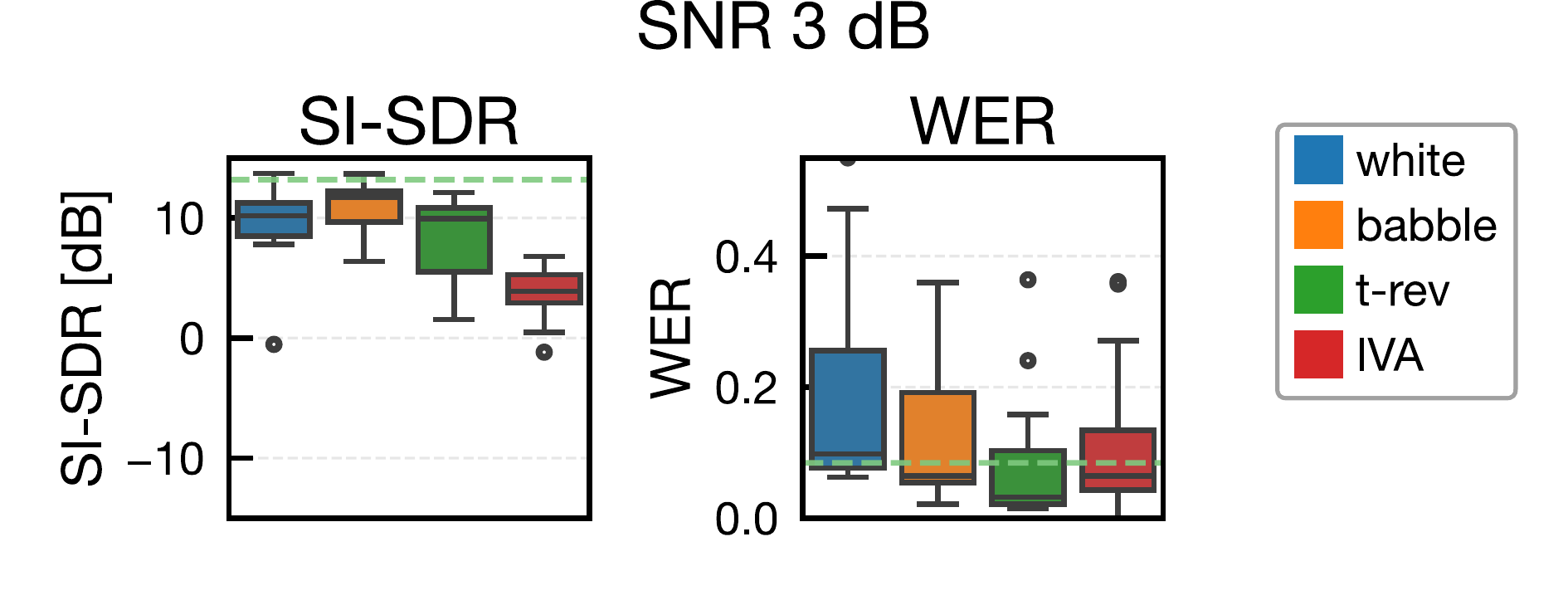
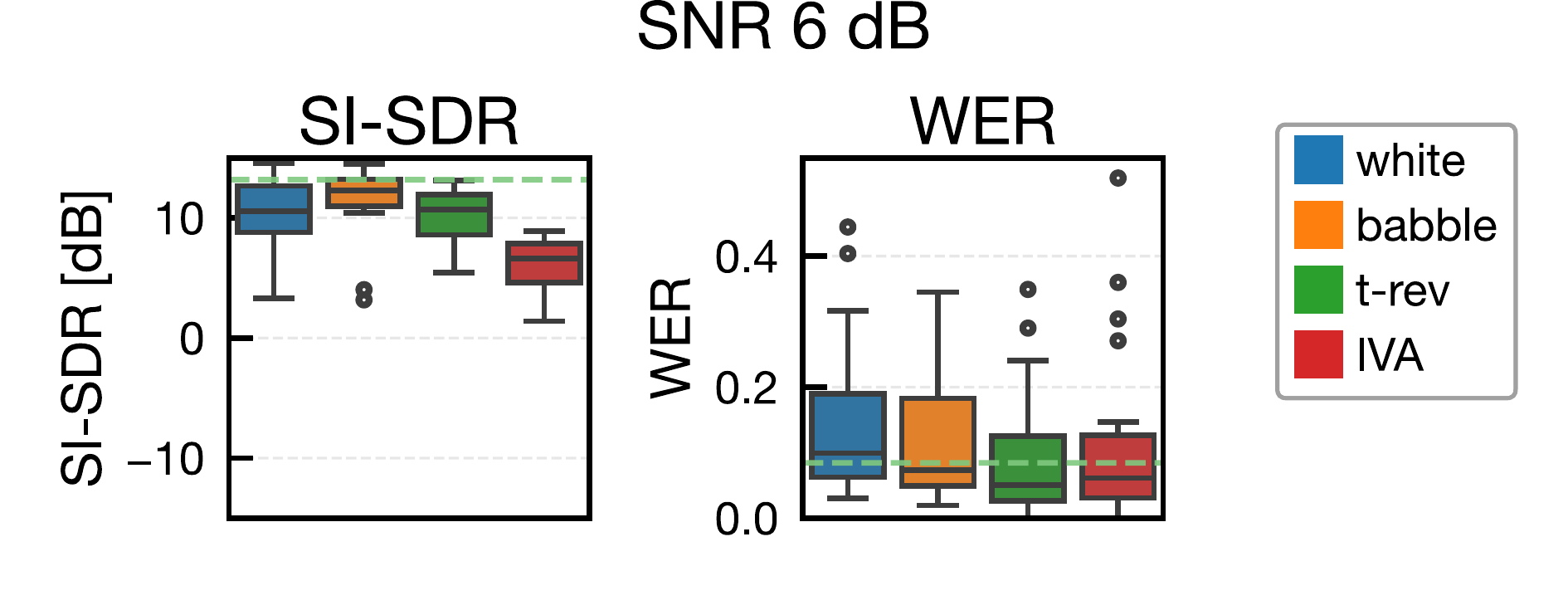
ジャミング信号用スピーカと,ジャミング生成用の追加マイクは話者近傍(話者中心から y 軸方向に 0.3 m)に配置しました。比較手法は white(白色雑音),babble(雑談雑音),t-rev(時間反転マスキング),IVA(提案法)で,SNR は -6, -3, 0, 3, 6 dB の 5 条件で評価しました。t-rev は時間反転マスキングの先行研究を参考にしています [5]。
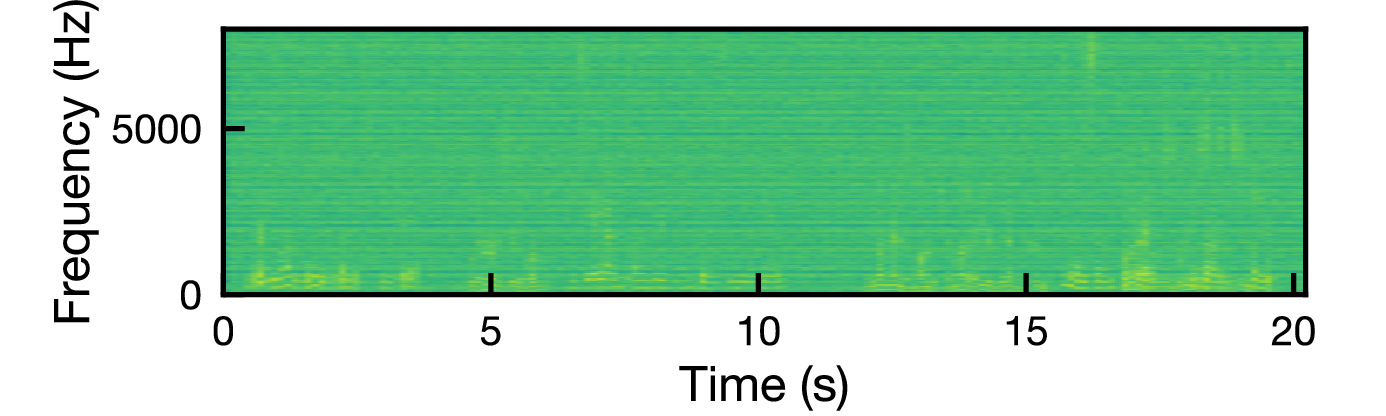
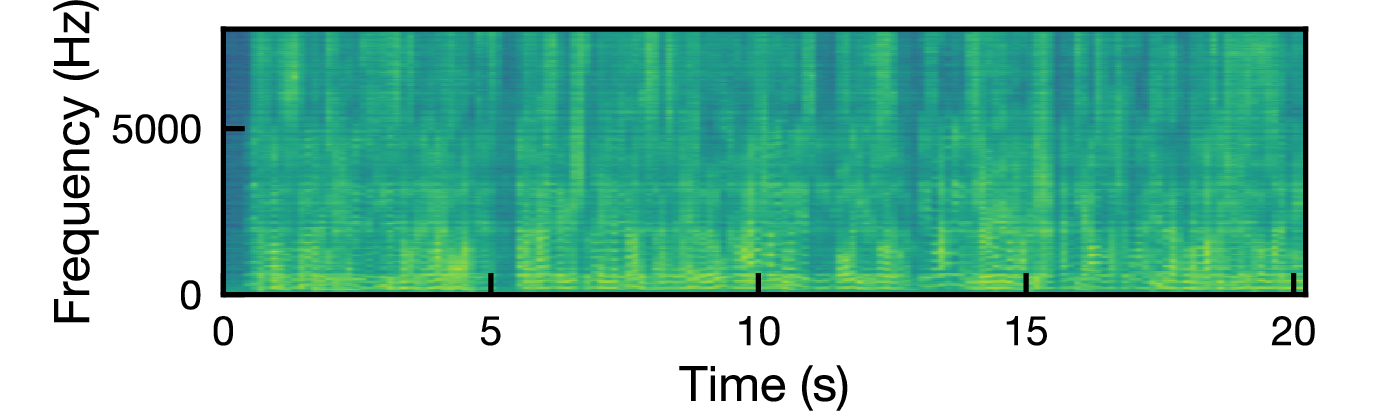
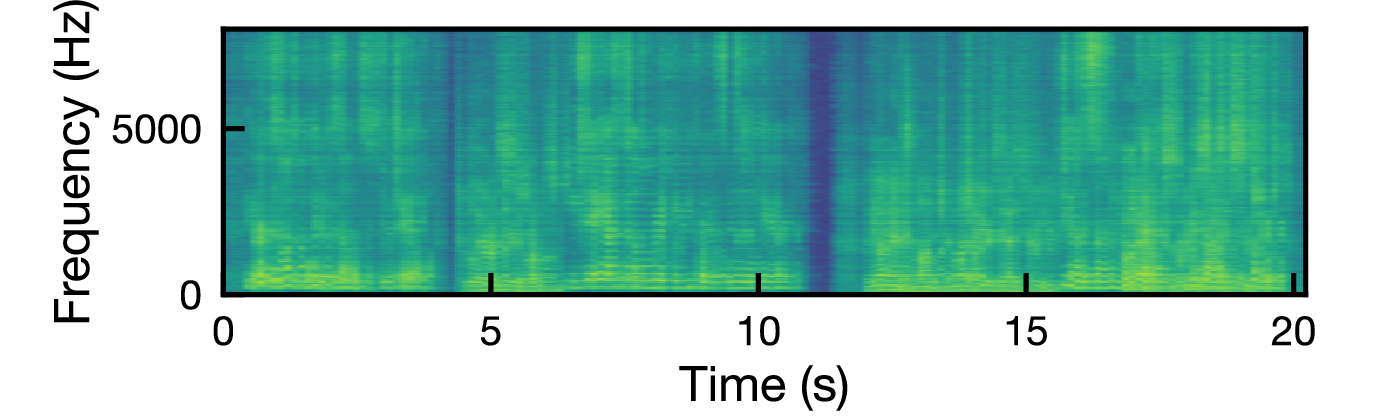
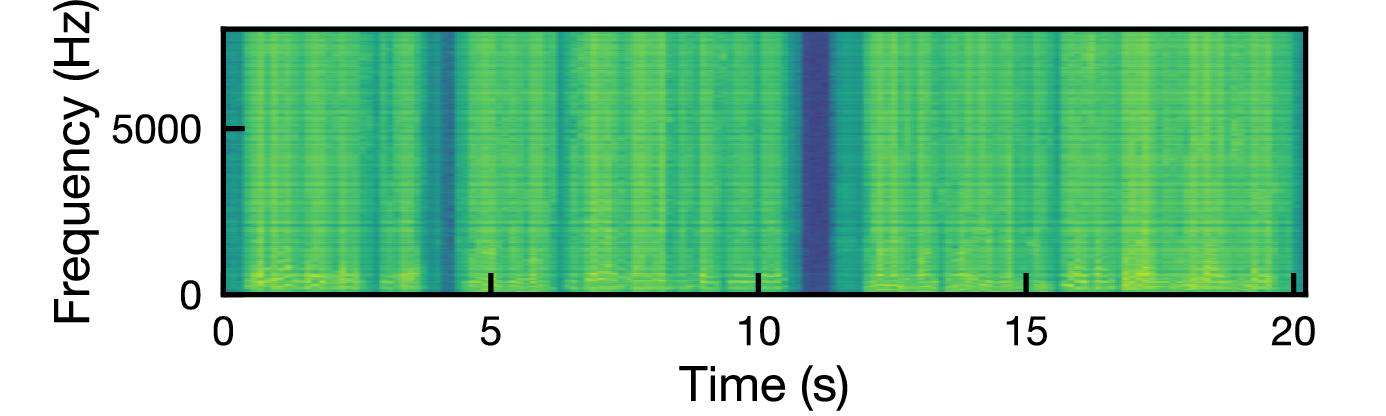
図: 各ジャミング信号に対する混合信号のスペクトログラム(上から white, babble, t-rev, IVA)
データセット
音声データには LibriSpeech の test-clean を使用し,2 話者の 16 kHz・20 秒混合音を作成しました [16]。各発話の最大長は 5 秒,重なり確率は 0.35 とし,重なり開始タイミングや休止時間は乱数で制御しています。さらに音源・マイク配置も変化させ,各条件につき 20 サンプルを生成しました。
分離パラメータ
分離アルゴリズムは pyroomacoustics 実装の AuxIVA(時間変動複素ガウスモデル)を使用し,反復回数は 50 回です [12], [13]。STFT 条件は窓長 4096,シフト 2048,Hann 窓としました。分離後は projection back を適用してスケール補正し,SI-SDR と WER で評価しました。SI-SDR は fast-bss-eval,WER は SpeechBrain の Wav2Vec2(LibriSpeech 学習済みモデル)で算出しています [17], [18]。なお,white の一部低 SNR 条件では特異行列エラーにより分離不能サンプルが発生し,集計から除外されています。
結果
音声サンプル
各プレビューは再生時に波形とスペクトログラムを読み込みます。スペクトログラムは 16 kHz 音声に合わせて 0--8 kHz を表示しています。
auxiva babble t-rev white 結論
提案法(IVA)は,全 SNR 条件で SI-SDR を最も低下させ,BSS に対する妨害効果を確認しました。対照的に,白色雑音やバブル雑音は SI-SDR が比較的高く,従来型マスキングのみでは BSS 盗聴を十分に抑止できない可能性が示されました。t-rev は white / babble より分離性能を低下させましたが,提案法には及びませんでした。
WER の観点では,提案法が常に最悪値になるわけではなく,一部条件で babble と同程度でした。これは提案ジャミングが元信号の位相情報を利用しているため,音声認識に利用可能な手がかりが残る可能性を示唆しています。今後は,より強いジャミング設計,深層学習系分離器・音声強調器に対する評価,および実環境での聞き取りやすさ・不快感の主観評価が重要な課題です。
参考文献
- Jide S. Edu, Jose M. Such, and Guillermo Suarez-Tangil, "Smart Home Personal Assistants: A Security and Privacy Review", ACM Computing Surveys, 2021, doi: https://doi.org/10.1145/3412383
- Chen Yan, Xiaoyu Ji, Kai Wang, Qinhong Jiang, Zizhi Jin, and Wenyuan Xu, "A Survey on Voice Assistant Security: Attacks and Countermeasures", ACM Computing Surveys, 2022, doi: https://doi.org/10.1145/3527153
- Luca Hernandez Acosta and Delphine Reinhardt, "A survey on privacy issues and solutions for Voice-controlled Digital Assistants", Pervasive and Mobile Computing, vol. 80, pp. 101523, 2022, doi: https://doi.org/10.1016/j.pmcj.2021.101523
- Jacob Donley, Christian Ritz, and W. Bastiaan Kleijn, "Improving speech privacy in personal sound zones", Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 311–315, Mar. 2016, doi: https://doi.org/10.1109/ICASSP.2016.7471687
- Takayuki Arai, "Masking Speech with Its Time-Reversed Signal", Acoustical Science and Technology, vol. 31, no. 2, pp. 188–190, 2010, doi: https://doi.org/10.1250/ast.31.188
- Pierre Comon and Christian Jutten, "Handbook of Blind Source Separation: Independent component analysis and applications", 2010
- Yuchen Liu, Ziyu Xiang, Eun Ji Seong, Apu Kapadia, and Donald S. Williamson, "Defending Against Microphone-Based Attacks with Personalized Noise", Proceedings on Privacy Enhancing Technologies, vol. 2021, no. 2, pp. 130–150, 2021, doi: https://doi.org/10.2478/popets-2021-0021
- Peng Huang, Yao Wei, Peng Cheng, Zhongjie Ba, Li Lu, Feng Lin, Fan Zhang, and Kui Ren, "InfoMasker: Preventing Eavesdropping Using Phoneme-Based Noise", Proceedings of the Network and Distributed System Security Symposium (NDSS), 2023, doi: https://doi.org/10.14722/ndss.2023.24457
- Ming Gao, Yike Chen, Yajie Liu, Jie Xiong, Jinsong Han, and Kui Ren, "Cancelling Speech Signals for Speech Privacy Protection against Microphone Eavesdropping", Proceedings of the ACM Annual International Conference on Mobile Computing and Networking (MobiCom), pp. 1–16, 2023, doi: https://doi.org/10.1145/3570361.3592502
- Pierre Comon, "Independent Component Analysis, a New Concept?", Signal Processing, vol. 36, no. 3, pp. 287–314, Apr. 1994, doi: https://doi.org/10.1016/0165-1684(94)90029-9
- Taesu Kim, Hagai T Attias, Soo-Young Lee, and Te-Won Lee, "Blind source separation exploiting higher-order frequency dependencies", IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 15, no. 1, pp. 70–79, Jan. 2006
- Nobutaka Ono, "Stable and fast update rules for independent vector analysis based on auxiliary function technique", Proceedings of IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), pp. 189–192, Oct. 2011, doi: https://doi.org/10.1109/ASPAA.2011.6082320
- Nobutaka Ono, "Auxiliary-function based independent vector analysis with power of vector-norm type weighting functions", Proceedings of Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), pp. 1–4, Dec. 2012
- Matthew Anderson, Geng-Shen Fu, Ronald Phlypo, and Tulay Adali, "Independent Vector Analysis: Identification Conditions and Performance Bounds", IEEE Transactions on Signal Processing, vol. 62, no. 9, pp. 2274–2286, 2014, doi: https://doi.org/10.1109/TSP.2014.2333554
- Robin Scheibler, Eric Bezzam, and Ivan Dokmanic, "Pyroomacoustics: A Python Package for Audio Room Simulation and Array Processing Algorithms", Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 351–355, Apr. 2018, doi: https://doi.org/10.1109/ICASSP.2018.8461310
- Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur, "LibriSpeech: An ASR Corpus Based on Public Domain Audio Books", Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5206–5210, 2015, doi: https://doi.org/10.1109/ICASSP.2015.7178964
- Jonathan Le Roux, Scott Wisdom, Hakan Erdogan, and John R. Hershey, "SDR — Half-baked or Well Done?", Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 626–630, May 2019, doi: https://doi.org/10.1109/ICASSP.2019.8683855
- Robin Scheibler, "SDR — Medium Rare with Fast Computations", Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 701–705, 2022, doi: https://doi.org/10.1109/ICASSP43922.2022.9747473